Yesterday’s archives can’t handle the challenges of today’s modern enterprise, let alone the challenges enterprises are bound to face in the future as communication channels rapidly evolve. The variety of communication sources has dramatically increased to include text messaging, unified communications, enterprise collaboration, social media, and more.
Old school archives were built at a time when an organization’s primary communication vehicle was email, and dynamic sources like Microsoft Teams and Slack had not yet gained massive popularity. Expecting these antiquated archives to perform in today’s world is akin to using your grandparents’ landline phone as a primary mode of contact.
So how do today’s archives differ from the archives of yesteryear? To start, they are designed for the cloud. Cloud-based archiving has been touted as the next generation of content storage for years, given the cost, maintenance, and ongoing support advantages. However, the market now realizes that not all cloud archives are created equal.
The first cloud archives were simply hosted versions of the monolithic on-premises systems and suffered from the same performance and cost problems. Other early cloud archives have been deployed in vendor-managed data centers and don’t adequately exploit the advantages of standards-based cloud infrastructure, security, and management offered by market leaders such as Amazon Web Services (AWS) and Microsoft Azure. What too many customers have realized is that managing one’s own data center does little to help one innovate.
Next, today’s modern archives do not force companies to convert rich content from unified communications, IM, and social networks into email to be reviewed. Understanding the context of a conversation that took place across multiple posts and networks is not easy if that content is archived as 20 distinct email messages. Crucial posts can easily be missed, and legal teams could waste hours attempting to piece together a conversation thread to find out what really transpired.
To be suited for today’s enterprise, an archive should have the following qualities:
Dynamic Scaling
Enterprise users generate millions of data every day in various forms, including emails, instant messages and persistent chats, blogs, wiki pages, and social media posts. Given the ever-growing data sources that should be archived, governed, and made discoverable, archives have to keep up with this volume and variety of data.
“Cloud-based archives are not created equally. Archive vendors who manage their own data centers do not help you innovate.”
For example, collaboration tools alone create more communication volume and complexity. Posts are enveloped in important event metadata that tell the full story of who participated in a meeting and what interactions they engaged in – sometimes amounting to hundreds or thousands of participants and actions. Without the metadata, review and governance of these communications is next to impossible, as there is no correlation of one post, thread, or tweet to another
The modern cloud archive must also be designed to handle the ingestion of both real-time and historical data from legacy sources. This requires dynamic scaling to support spikes in data volume and variety arriving at any point in time.
Fast Throughput
When volumes swell in legacy archives, performance suffers because the underlying design is unable to allocate computing resources to where they are most needed. Adding resources to ingestion or indexing, for example, tends to negatively impact resources available for other tasks, such as search. Early cloud archives attempted to manage this by adding resources vertically (e.g., more servers), often buying more than required and incurring unnecessary cost.
In contrast, employing a modern cloud archive that leverages today’s infrastructure standards allows firms to scale components of the system independently. This allows firms to manage ingestion, indexing, search, and export uniquely, and scale up or scale down use – and pay for – only the resources necessary to maintain ingestion, search, or export SLAs. In the end, one of a cloud archive’s greatest values is its ability to deliver content to other applications and workflows that need it.
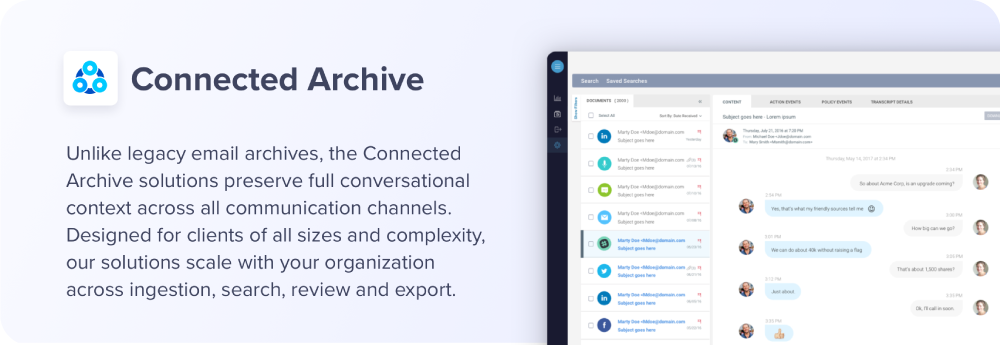
Context-Aware Playback
With a traditional archive, reviewers can’t understand the relationship between and among emails unless they spend a great deal of time combing a series of independent messages in an attempt to understand their relationship. Email threading works for flat, static, text-based communications, but not for today’s multi-modal, interactive communications sources.
Smart archive solutions must save the entire conversation thread and event information for an accurate transcript of the conversation, even if a portion of a conversation has been edited or deleted or jumped to other communications networks. Reviewers can thereby appreciate the relevance of complex interaction events, such as real-time chat, blog entries, or discussion board comments, in a single view.
Communication and collaboration patterns have radically changed within the past five years, and it’s time to retire outdated email-centric technologies. First-generation hosted and vendor-managed data center solutions provided an early attempt to address the challenge, but have become obsolete with the evolution of cloud infrastructure standards. Armed with a smart, cloud-based archive, firms can fully leverage the advantages of the cloud in order to better meet the needs of today’s clients, prospects, and employees.

- 5 Questions to Ask Before Choosing an AI Model Provider - July 14, 2026
- Build or Buy? The LLM Decision Your Compliance Team Needs to Own - July 10, 2026
- Why AI Communications Governance Is a Risk Discipline - June 17, 2026
